We constantly hear about data flows in very different contexts, from those generated within gaming software to those related to purchases made on e-commerce portals. We are part of a large machine that continuously produces a huge amount of data.
Let’s imagine the world composed of a gigantic stream of data (or data streaming as we will call it later), by countless streams of data.
Each data, whether taken individually or clustered, can generate enormous value in terms of business and, more generally, of knowledge. This flow cannot by its nature be immobile but, on the contrary, in continuous becoming. To interpret this data flow you need to have the ability to capture, analyze, and extract the intrinsic value of data in real time.
Well, we can now start from the beginning.
What is Data streaming?
It is a data management mode that operates in real time by intercepting the multiple flows and, at the same time, carrying out a series of analyses and operations on them. This type of “synchronous” management exceeds the “asynchronous” one traditionally used by loading data into ad hoc structures to subject them to subsequent analysis (batch processing).
It allows to:
- receive data in real time (message broking)
- process data in real time (data enrichment)
- store data (storage)
The data is generated continuously from different sources that thus generate a flow that is transmitted and analyzed in real time or in some cases in “almost” real time (near real time).
The Data Streaming approach makes use of the capabilities of the chosen technology to carry out continuous mathematical or statistical analysis within the data stream. Stream processing solutions are in fact designed to manage large volumes in real time with a scalable architecture following these characteristics:
- processing of large amounts of events
- real time answears
- performance and scalability (data volumes increase in size and complexity without lowering efficiency)
- rapid integration with existing infrastructures
- alerting systems
How important is the Real-time factor?
Getting the highlights at the right time.
Sounds pretty important doesn’t it? In fact, it is precisely the variable time that often makes the difference in the quality of service, both if we talk about customer assistance or services that require continuity of service. The information, captured and analyzed, not only allows a broader view of the business to companies, but allows timely and, consequently, effective responses.
For example, companies can monitor changes in customers’ buying tastes and behaviors and quickly change offers, services or models for sale. Or again: factories can optimize production according to actual and real demand and not looking at “projections” estimated a priori.
It often happens to understand the concept of a certain notion, technology or specific mode in an abstract way, but without being able to really grasp its concrete use, the needs it satisfies and its applicability in the real world.
To avoid that this is also one of those cases here, are some real examples!
In the industrial and agricultural field, streaming applications, thanks to the sensors associated with machinery and devices that collect data, can monitor performance and anticipate stops and failures, improving the efficiency of the production system.
In the energy sector, this type of technology is useful, for example, to monitor in real time the status of photovoltaic panels or the amount of energy in transit, having the possibility to constantly manage the energy yield and to provide for maintenance interventions on the devices.
For online gaming, huge amounts of data related to the game itself and the interactions between players are collected. In this case it is possible to analyze this data in real time to create ad hoc answers or offers, increasing customer satisfaction, involvement in the game itself and hopefully loyalty to the service.
For health & fitness, medical equipment and fitness trackers, equipped with sensors, collect and transmit information for certain medical decisions or more generally monitor activities related to sleep, nutrition and training. The real-time transmission and analysis of this information makes the service valuable and real support both to experts in the field and to the users themselves.
For e-commerce, inventory management is important for customer satisfaction. When you make a purchase, the purchased item is removed from inventory. What happens if I buy the last item of its kind, at a certain time, at the same time as another user? Simple. Only one of the two will have the chance to conclude the order successfully. For the unfortunate it will only remain a bad user experience, since he will be made aware of the lack of the product in inventory at the beginning or almost completed purchase process.
Thanks to real-time updates of events, the user can be informed that the product is no longer available and the cart can be automatically emptied of products that can no longer be purchased at that time. In this way, not only is the service improved, but the customer’s purchase expectations are protected.
These are just some of the citable scenarios and sectors that we could consider.
Technically, how do you manage Data Streaming?
Without any doubt, in the opinion of all experts in the field, the best technology for designing streaming applications is Apache Kafka.
We started by explaining what data streaming is and imagine a series of real use cases to understand how it works and the potential for improvement for different types of service.
Now let’s move on to the technology:
What is Kafka?
One of the most performing and scalable open source solutions in Data Streaming.
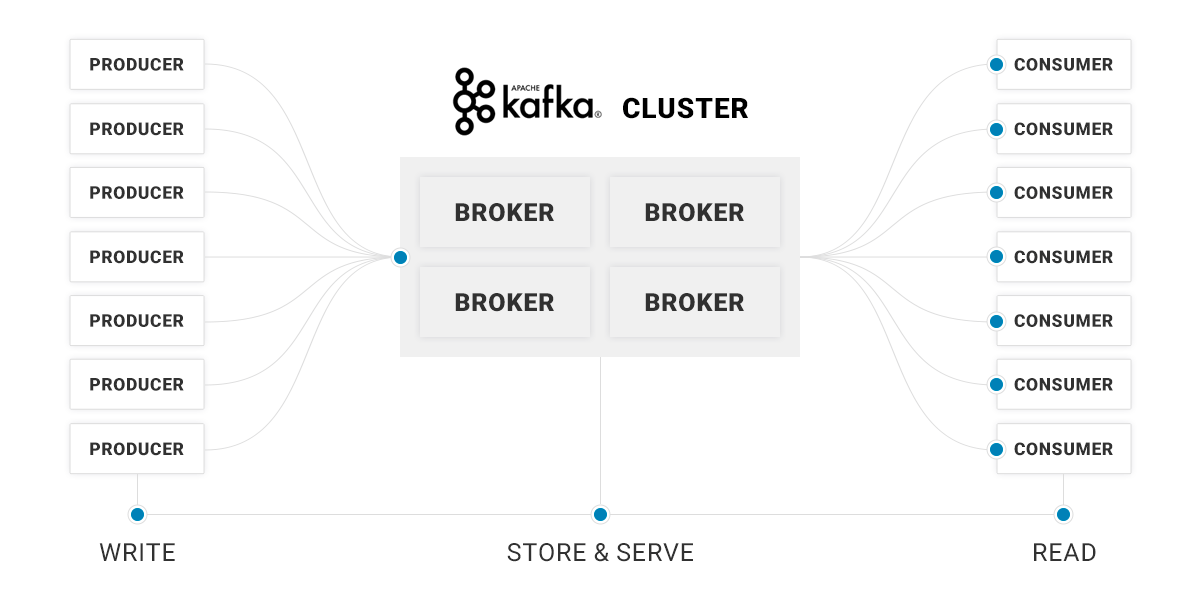
It is a distributed data streaming platform that allows you to publish, subscribe, store and process streams of records in real time. It allows you to receive data from different types of sources (called producers), processing them within its architecture and making them available to receivers (consumers).
It was born in 2010 from the need of one of the most famous social media in the world to manage the problems related to the management of large amounts of data on the web.
It is designed to manage data streams from multiple sources, producers, distributing them to multiple recipients, consumers. In short, it allows you to process large volumes of data, making them immediately available to users.
What is it used for and what would be the advantages?
Let’s start with the benefit of using Apache Kafka: users can take advantage of data in real time. And we have talked about the importance of this factor in certain contexts to get here.
Apache Kafka is integrated into data streaming streams that allow data to be shared between systems and/or applications, and can be used in all those cases where high speed and scalability are critical.
In big data issues, in application environments, such as the IoT (Internet of Things) and social media, where the volume of data growing steadily and quickly can compromise existing applications, Apache Kafka’s scalable processing allows you to respond correctly by managing the growth (sudden or constant) of data.
For example, Apache Kafka enables users to consume data faster, thanks to its ability to minimize the use of point-to-point integrations for sharing data in certain applications, reducing latency to milliseconds. An advantage that is far from negligible for certain services, such as e-commerce, of which we have previously mentioned a use case, which in the timeliness of updating data and analyzing it is based on a large part of the quality of the service offered.
Conclusions
The characteristics of this technology have led our technical team to approach this world for some years, becoming today experts of Apache Kafka.
Contact our experts to learn more about Apache Kafka!